
At long last... the great dumpster fire that was 2020 is no more. There's certainly a lot I'd like to leave behind us. But like a phoenix rising from the ashes, I want to highlight some amazing tools and practices that actually made my life better as a web developer 🚀
I wrote a similar post back in 2019 once I really found my footing in the web dev space. Now, I'm gonna make this a yearly tradition! 🥳
Let's jump into:
- 🌳 4 Git snippets that defined my workflow
- 🧠 My mission to build a second brain in VS Code
- ⚙️ Discovering that everything is a state machine with XState
- 🐏 The joys of functional programming in JS using Ramda
Onwards!
4 Git snippets I use daily
I started my first full-time job as a programmer this year, which means I've been picking up a lot of new tricks in a pretty quick timeframe. Naturally, I started automating the workflows I use day-in and day-out 😁
Stop me if you've seen this workflow before:
- I picked up a ticket on JIRA
- I need to pull the latest main branch
- I need to checkout a new branch
- I need to push that branch to origin to and collaborate with my team and open my PR
I'll probably do this 5+ times in one day if we're in a bug-squashing flow. But when I'm hurrying, it's so easy to either a) work off an old "main" branch, or b) do the copy-paste of shame before your PR:
To push the current branch and set the remote as upstream, use
git push --set-upstream origin crap-not-again
You know you cringe a little every time this pops up 😬
To mitigate this, I've created my fantastic 4 shortcuts for slamming through my daily tasks 💪
# Stash what I'm working on and checkout the latest master
alias gimme="git stash push -u && git checkout master && git pull -r"
# Grab the latest master and come back to the branch I was on (with stashing!)
alias yoink="gimme && git checkout - && git stash pop"
# Checkout a new branch and push it to origin (so I don't forget that set-upstream)
woosh() {
git checkout -b $1 && git push -u origin HEAD
}
# ALL TOGETHER NOW
# Stash my current WIP, checkout a new branch off the latest master, and push it to origin
alias boop="gimme && woosh"
Let's understand what these commands are doing a little more:
gimme:This command assumes you might not be on the main branch just yet. It will first stash anything you're working on, including "untracked" / new files with the-uflag. Then, it will head over to the main branch and pull the latest. That-rflag will be sure to "rebase" onto the latest, preventing unecessary merge conflicts.yoink:This builds off ofgimmea little bit. Instead of remaining on the main branch when we're done, we'll head back to the branch we were just on using the-parameter. This is super convenient for grabbing the latest changes to force rebase the branch we're working on.woosh:This fixes our--set-upstreamproblem from earlier. Instead of pushing to origin later, this lets you check out a new branch and push right away. Yes, there's some cases when you don't want your local branch on the remote, but this is pretty rare in my experience. And if you've never seen theHEADparameter before... remember that one! It's a super slick way to auto-fill the name of your current branch instead of typing it out by hand 🔥boop:This command goes full-circle. It'll stash your current work, grab the latest main branch, and push it up to origin before you start working. This is the command I use the most!
Also gonna mention Jason Lengstorf (the lord of boops) for the naming convention here 😁
Building a second brain in VS Code
This year was all about writing, writing and more writing for me. There's just so much knowledge to pick up as a new full stack developer, yet it always feels so difficult to find what I wrote even a week ago!
I've struggled from notetaking app fatigue for years now. But at long last... I think I've found a semi-perfect home for everything I write both on and off the clock.
Enter the second brain 🧠
I'd been hearing about this concept for a while now, but never realized it's an actual strategy to notetaking. As you'd expect, it's all about writing as much as possible, so you can build a brain's worth of knowledge in note form.
This concept starts with the Zettelkasten Method used back in the pen-and-paper ages. It's built on some pretty basic principles:
- Every note is treated as a unique collection of thoughts, tagged by a unique ID of some sort
- Notes should form an ever-sprawling tree of connected ideas / thoughts. This is pulled off with "links" between notes (references to those unique IDs), much like hyperlinks on the web!
- You may index multiple "trees" of notes with tags or tables of contents, assuming your Zettelkasten grows pretty large
There's countless nuggets of advice on how to do a Zettelkasten right. But overall, it's clear that a physical Zettelkasten maps perfectly to how the web works. So, why not use a bunch of HTML files to create one? Or better yet, markdown files?
Using VS Code + Foam
I discovered a project called Foam recently that's... not really a stand-alone project; it's a collection of extensions that work well together, with some helpful guides on how to make the most of them.
All you need to do is clone a repository and watch the magic happen! It'll recommend all the extensions you should need to edit, link, and view your notes. But at the end of the day, you're really just writing a bunch of markdown files on your computer + some added benefits.
Getting a birds-eye view 🗺
It's worth discussing a crucial part of the Foam style of notetaking: you never need to group notes by directory. We're so used to using file systems to organize everything, but let's be honest, that's not how our brain works!
Foam thrives on connecting notes with links, rather than folder hierarchies. This makes it much easier to define notes that might be referenced in a ton of places. Instead of finding the exact directory where a note should live, you just need to reference the file itself.
Foam will help you find any patterns that naturally emerge from links with a graph visualization extension. It's basically one big map of your head that you can click into and explore!
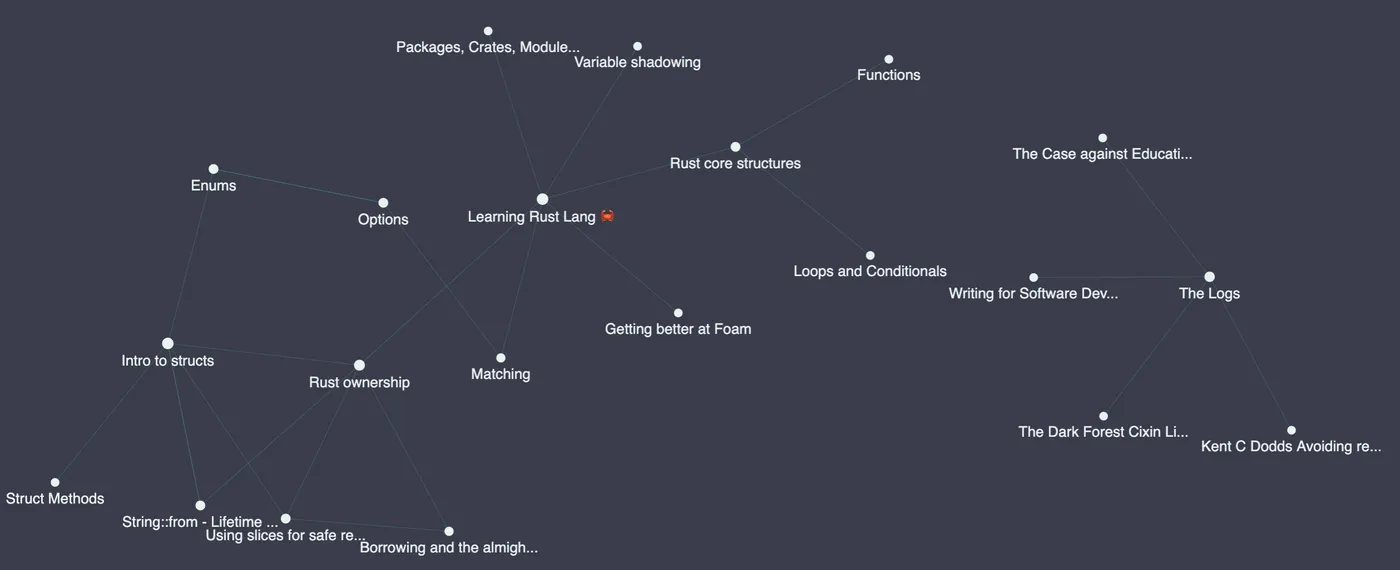
This is the graph generated by my recent challenge to learn Rust lang. Notice how this doesn't quite match up to a parent-child relationship that directory trees demand. For instance, "Intro to structs" on the far left gets referenced by "Enums" and "Rust ownership." But you couldn't have the same file sitting in multiple directories at once! That's the beauty of using free-form links; anything can reference anything else, so it's less of a tree and more of a purposeful, tangled-up birds nest 😁
Metaphor for my brain
If you use VS Code every day like me, this is super easy to dive into for the first time. Definitely give it shot if blog more is one of your New Year's resolutions 🎉
Everything is a state machine
You're a state machine. I'm a state machine. The world is a state machine.

...okay jokes aside, state machines really do apply to everything 😆
You may have heard of XState as a solution to "global state management" in your JS apps. This is true, but the idea of state machines is more of a way of thinking than just another library to learn.
Visualizing your state
Diagramming is really XState's bread and butter. With most state management tools, the actual progression from one action / state / reducer to another can be pretty tough to trace. In XState, they have a dedicated sandbox to work from!
Let's break down some important XState lingo here:
- Finite states are those words surrounded by a rectangle (idle, loading, etc.). If you come from Redux like me, you can look at each of these like mini-reducers. They each have unique actions that they're listening for, which may cause you to progress from one reducer to the next.
- Actions are defined by those gray bubbles between our finite states (FETCH, RESOLVE, etc.). These can do a few interesting things: progress you to another finite state, set some "global" state for the whole machine (see the next bullet), or fire off some "side effects" that do things outside the machine. For instance, the
FETCHaction might kick off an API call of some sort. If that API call comes back successfully, we'll fire theRESOLVEaction (which our "loading" state picks up). - Context is some global state shared by all states in the machine. This is just one big JS object you can assign new values to and read from whenever you want. In this case, we have a count of how many times we "retried" our fetch, which gets updated on the
RETRYaction withdo / assign retries
This approach has countless benefits, but the biggest one for me: you can use any framework you want with XState, or even no framework at all! This makes me super comfortable going all-in on the library since I can take it with me wherever I go 😁
To get your feet wet in this brave new world, I found some high quality demos around the Internet worth checking out:
- This one on modeling UI with state machines across frameworks. Best conference talk on the subject hands down.
- This one on building a more complex ReactJS form. It's longer, but worth your time!
- This one on creating a Vanilla JS drag-and-drop interaction. This is more CSS-intensive and speaks to the
classNametrick I showed above.
One-line state machines with TypeScript
I started using this pattern more and more throughout the year. This actually doesn't use any libraries at all! In short, it's neat shorthand to collapse an ever-growing sea of booleans:
const [formIdle, setFormIdle] = React.useState(true);
const [formInvalid, setFormInvalid] = React.useState(true);
const [formSubmitting, setFormSubmitting] = React.useState(true);
const [formSubmitted, setFormSubmitted] = React.useState(true);
...into a single, type-safe state:
type FormState = 'idle' | 'invalid' | 'submitting' | 'submitted'
const [formState, setFormState] = React.useState<FormState>("idle");
This fixes the age-old problem tools like Redux seemed to encourage: you have a bunch of booleans representing unique states, but only one boolean should be flipped "on" at a given time. It's a hassle making sure all your boolean's are false when they're supposed to be, so why not have a boolean with more than 2 states?
There are a number of other benefits to this approach like flipping CSS classes at the right times. Check out this article for some interactive code examples ✨
Functional programming with RamdaJS
Across the tech stack my full-time job demands, functional programming has been the common thread for me to pick up.
The functional programming community has flourished with all the static type checking goodness that TypeScript brought. Heck, there's an entire helper library for nearly every concept in the category theory book!
My knowledge of true, mathematical FP is still very surface level right now. Still, I've definitely found my "gateway drug" into this new world: I need to transform a big blob of data into a different looking blob of data, and I'm gonna chain 10 functions together to do it 😎
RamdaJS really is the missing toolkit JS needs for these acrobatics. I could ramble about each little function in their every-sprawling docs, but let's hit the biggest highlights.
Boolean operations
First off, Ramda throws you some nice shortcuts for combining multiple arrays. Let's consider some basic inventory management for our coffee shop. Before someone can check out, we need to exclude any items that are out of stock. Normally, we'd write some function like this one:
const orders = ["Macchiatto", "Cold brew", "Latte"]
const outOfStockItems = ["Macchiatto"]
const validOrders = orders.filter(order => !outOfStockItems.includes(order))
This works well enough... but it's not super readable. Watch us rewrite this sort of operation in a single stroke:
// subtract out all the outOfStockItems from orders
const validOrders = difference(orders, outOfStockItems)
// -> ["Cold brew", "Latte"]
We can do all kinds of things from here! For instance, we could filter out multiple arrays at once by unioning them together:
const validOrders = difference(orders, union(outOfStockItems, itemsOutForDelivery))
...or figure out which items we should include using a SQL-inspired innerJoin:
// basically, filter our menuItems based on which ones were ordered
const itemsOrdered = innerJoin((item, order) => item.name === order, menuItems, validOrders)
Boolean operations like these are certainly not a unique concept. Still, I'm glad Ramda includes all of them with a nice REPL playground to boot. If it's your first time seeing boolean operations, I highly recommend this interactive tutorial 🔥
Formatting in bulk with evolve
Okay, this helper really blew my socks off. I'm sure you've run into this sort of pattern before when you try to transform one object into another one:
const orders = [{
name: "Macchiatto",
options: {
roomForCream: true,
cream: {
quantity: "1tbsp"
}
}
}...]
// now, we want to loop over all of these and convert that "quantity" to an int.
orders.map(order => ({
// make sure the name sticks around
...order,
options: {
// and roomForCream
...order.options,
cream: {
// ...and finally, parse quantity to an int
quantity: parseInt(order.options.cream.quantity)
}
}
}))
Not bad, but all that dot chaining is making my head spin. We also have to remember all of the keys at each level so they don't disappear on us. The spread operator cleaned up this process for us, but it's still easy to forget (especially if you don't have type checking!). If only we could just modify the keys we care about, without all the nested dots.
This is exactly with evolve does! 🎉
orders.map(
evolve({
// ignore the properties we *don't* want to change, like the name
options: {
// ignore roomForCream too
cream: {
// and just put a reference to the parseInt function as-is. Don't even call it!
quantity: parseInt
}
}
})
)
There's some serious benefits to this approach. Not only can we omit keys we don't want to change, but we can modify deeply nested fields without much trouble! You'll also notice we can just pass evolve into our map directly, without passing in the order like we're used to doing (i.e. map(order => evolve(order))). This is because all Ramda functions are curried, which you can learn a bit more about from this Stack Overflow answer 😁 Spoiler: it's an awesome feature.
And that's a wrap!
I know 2020 hit a lot of people hard this year. If you're struggling with family, dealing with kids at home, finding a new job, losing your mind indoors... well, at least you made it through to today 🙂
If you have anything else that made your life better as a developer or as a person, please drop them in the comments on the DEV version of this post. Would love to hear some fresh perspectives as we all take a fresh start for 2021!